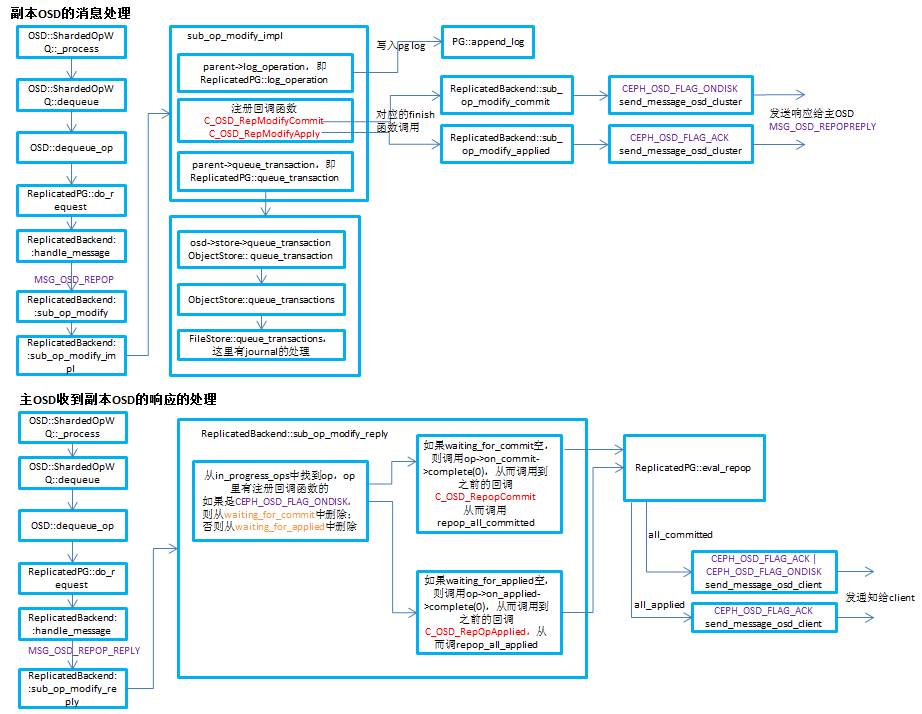
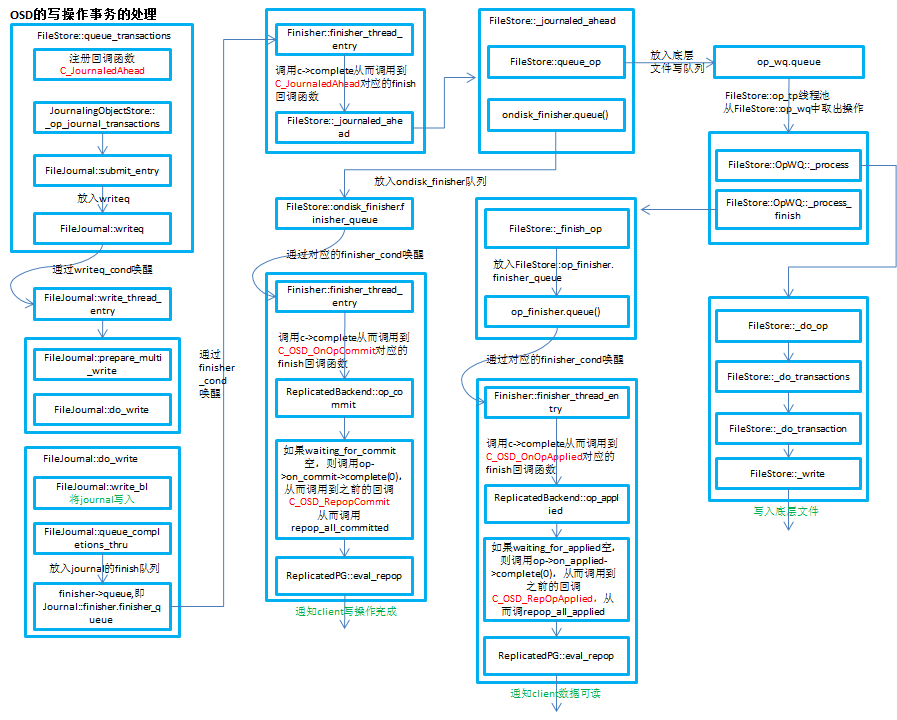
ceph的PGLog是由PG来维护,记录了该PG的所有操作,其作用类似于数据库里的undo log。PGLog通常只保存近千条的操作记录(默认是3000条),但是当PG处于降级状态时,就会保存更多的日志(默认是10000条),这样就可以在故障的PG重现上线后用来恢复PG的数据。本文主要从PGLog的格式、存储方式、如何参与恢复来解析PGLog。
1.PGLog的格式
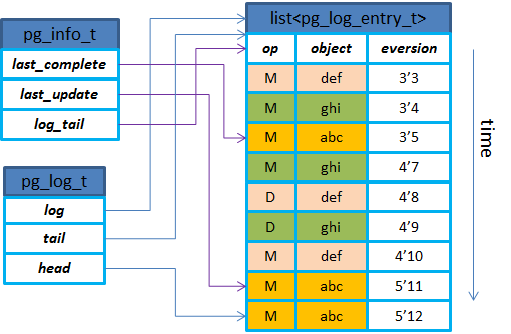
ceph使用版本控制的方式来标记一个PG内的每一次更新,每个版本包括一个(epoch,version)来组成:其中epoch是osdmap的版本,每当有OSD状态变化如增加删除等时,epoch就递增;version是PG内每次更新操作的版本号,递增的,由PG内的Primary OSD进行分配的。
PGLog在代码实现中有3个主要的数据结构来维护:pg_info_t,pg_log_t,pg_log_entry_t。三者的关系示意图如下。从结构上可以得知,PGLog里只有对象更新操作相关的内容,没有具体的数据以及偏移大小等,所以后续以PGLog来进行恢复时都是按照整个对象来进行恢复的(默认对象大小是4MB)。