ceph的PGLog是由PG来维护,记录了该PG的所有操作,其作用类似于数据库里的undo log。PGLog通常只保存近千条的操作记录(默认是3000条),但是当PG处于降级状态时,就会保存更多的日志(默认是10000条),这样就可以在故障的PG重现上线后用来恢复PG的数据。本文主要从PGLog的格式、存储方式、如何参与恢复来解析PGLog。
1.PGLog的格式
ceph使用版本控制的方式来标记一个PG内的每一次更新,每个版本包括一个(epoch,version)来组成:其中epoch是osdmap的版本,每当有OSD状态变化如增加删除等时,epoch就递增;version是PG内每次更新操作的版本号,递增的,由PG内的Primary OSD进行分配的。
PGLog在代码实现中有3个主要的数据结构来维护:pg_info_t,pg_log_t,pg_log_entry_t。三者的关系示意图如下。从结构上可以得知,PGLog里只有对象更新操作相关的内容,没有具体的数据以及偏移大小等,所以后续以PGLog来进行恢复时都是按照整个对象来进行恢复的(默认对象大小是4MB)。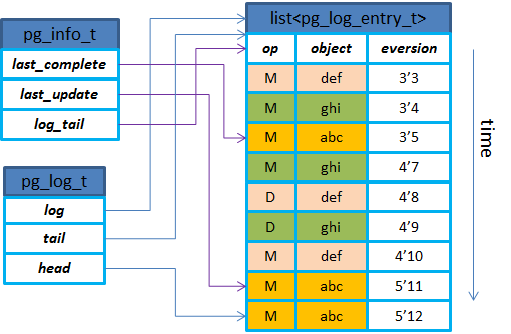
其中:
- last_complete:在该指针之前的版本都已经在所有的OSD上完成更新(只表示内存更新完成);
- last_update:PG内最近一次更新的对象的版本,还没有在所有OSD上完成更新,在last_update与last_complete之间的操作表示该操作已在部分OSD上完成但是还没有全部完成;
- log_tail:指向pg log最老的那条记录;
- head:最新的pg log记录;
- tail:指向最老的pg log记录的前一个;
- log:存放实际的pglog记录的list;
2.PGLog的存储方式
了解了PGLog的格式之后,我们就来分析一下PGLog的存储方式。在ceph的实现里,对于写I/O的处理,都是先封装成一个transaction,然后将这个transaction写到journal里,在journal写完成后,触发回调流程,经过多个线程及回调的处理后再进行写数据到buffer cache的操作,从而完成整个写journal和写本地缓存的流程(具体的流程在《OSD读写处理流程》一文中有详细描述)。
总体来说,PGLog也是封装到transaction中,在写journal的时候一起写到日志盘上,最后在写本地缓存的时候遍历transaction里的内容,将PGLog相关的东西写到Leveldb里,从而完成该OSD上PGLog的更新操作。
2.1 PGLog更新到journal
2.1.1 写I/O序列化到transaction
在《OSD读写流程》里描述了主OSD上的读写处理流程,这里就不做说明。在ReplicatedPG::do_osd_ops函数里根据类型CEPH_OSD_OP_WRITE就会进行封装写I/O到transaction的操作(即将要写的数据encode到ObjectStore::Transaction::tbl里,这是个bufferlist,encode时都先将op编码进去,这样后续在处理时就可以根据op来操作。注意这里的encode其实就是序列化操作)。
这个transaction经过的过程如下:1
2ReplicatedPG::OpContext::op_t –> PGBackend::PGTransaction::write(即t->write) –> RPGTransaction::write –> ObjectStore::Transaction::write(encode到ObjectStore::Transaction::tbl)
后面调用ReplicatedBackend::submit_transaction时传入的PGTransaction *_t就是上面这个,通过转换成RPGTransaction *t,然后这个函数里用到的ObjectStore::Transaction *op_t就是对应到RPGTransaction里的ObjectStore::Transaction *t。
2.1.2 PGLog序列化到transaction
- 在ReplicatedPG::prepare_transaction里调用ReplicatedPG::finish_ctx,然后在finish_ctx函数里就会调用ctx->log.push_back就会构造pg_log_entry_t插入到vector log里;
- 在ReplicatedBackend::submit_transaction里调用parent->log_operation将PGLog序列化到transaction里。在PG::append_log里将PGLog相关信息序列化到transaction里。
- 主要序列化到transaction里的内容包括:pg_info_t,pg_log_entry_t,这两种数据结构都是以map
2.1.3 Transaction里的内容
从上面的分析得知,写I/O和PGLog都会序列化到transaction里的bufferlist里,这里就对这个bufferlist里的主要内容以图的形式展示出来。transaction的bufflist里就是按照操作类型op来序列化不同的内容,如OP_WRITE表示写I/O,而OP_OMAPSETKEYS就表示设置对象的omap,其中的attrset就是一个kv的map。 注意这里面的oid,对于pglog来说,每个pg在创建的时候就会生成一个logoid,会加上pglog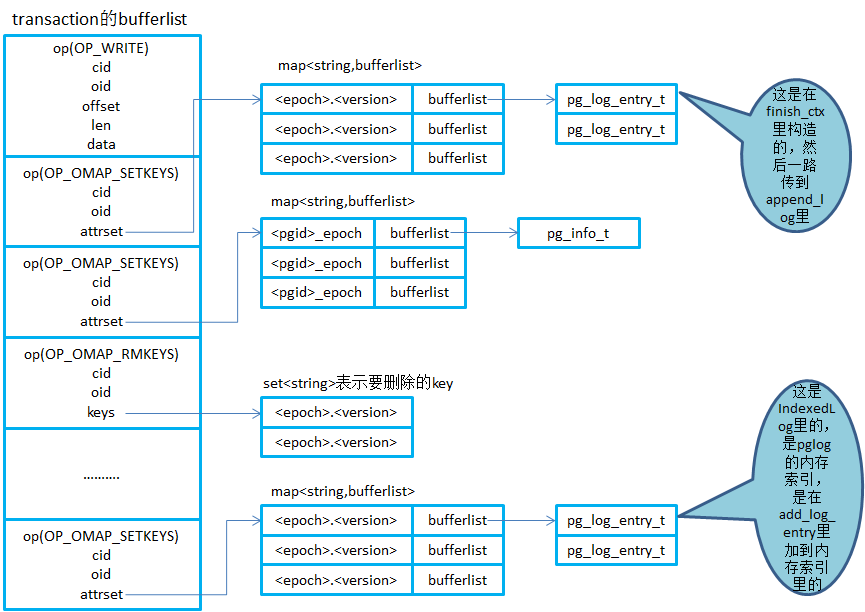
2.1.4 Trim Log
前面说到PGLog的记录数是有限制的,正常情况是默认是3000条(由参数osd_min_pg_log_entries控制),PG降级情况下默认增加到10000条(由参数osd_max_pg_log_entries控制)。当达到限制时,就会trim log进行截断。
在ReplicatedPG::execute_ctx里调用ReplicatedPG::calc_trim_to来进行计算。计算的时候从log的tail(tail指向最老的记录)开始,需要trim的条数=log.head-log.tail-max_entries。但是trim的时候需要考虑到min_last_complete_ondisk(这个表示各个副本上last_complete的最小版本,是主osd在收到3副本都完成时再进行计算的,也就是计算last_complete_ondisk和其他副本osd上的last_complete_ondisk–即peer_last_complete_ondisk的最小值得到min_last_complete_ondisk),也就是说trim的时候不能超过min_last_complete_ondisk,因为超过了的也trim掉的话就会导致没有更新到磁盘上的pg log丢失。所以说可能存在某个时候pglog的记录数超过max_entries。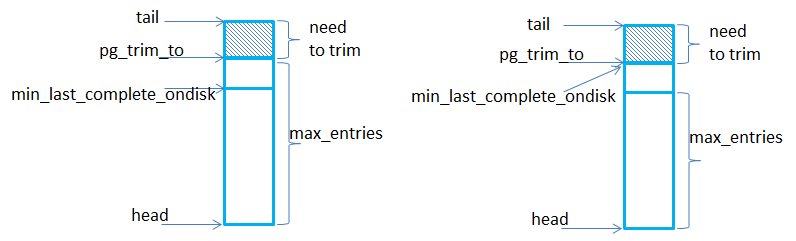
在ReplicatedPG::log_operation里的trim_to就是pg_trim_to,trim_rollback_to就是min_last_complete_on_disk。log_operation里调用pg_log.trim(&handler, trim_to, info)进行trim,会将需要trim的key加入到PGLog::trimmed这个set里。然后在_write_log里将trimmed里插入到to_remove里,最后在调用t.omap_rmkeys序列化到transaction的bufferlist里。
2.1.5 PGLog写到journal盘
PGLog写到journal盘上就是写journal一样的流程,具体如下:
- 在ReplicatedBackend::submit_transaction调用log_operation将PGLog序列化到transaction里,然后调用queue_transaction将这个transaction传到后续进行处理;
- 调用到了FileStore::queue_transactions里,就将list
- 接着在JournalingObjectStore::_op_journal_transactions函数里遍历list
- 然后FileJournal::submit_entry里将bufferlist构造成write_item放到writeq;
- 接着在FileJournal::write_thread_entry会从writeq里取出write_item,放到另外一个bufferlist里;
- 最后调用do_aio_write将bufferlist的内容异步写到磁盘上(也就是写journal);
2.2 PGLog写入leveldb
在《OSD读写流程》里描述到是在FileStore::_do_op里进行写数据到本地缓存的操作。将pglog写入到leveldb里的操作也是从这里出发的,会根据不同的op类型来进行不同的操作。
比如OP_OMAP_SETKEYS(PGLog写入leveldb就是根据这个key):1
FileStore::_do_op --> FileStore::_do_transactions --> FileStore::_do_transaction 根据不同的Transaction类型来进行不同的操作 --> case Transaction::OP_OMAP_SETKEYS --> FileStore::_omap_setkeys --> object_map->rm_keys,即DBObjectMap::set_keys --> KeyValueDB::TransactionImpl::set,遍历map<string, bufferlist>,然后调用set(prefix, it->first, it->second),即调用到LevelDBStore::LevelDBTransactionImpl::set --> 最后调用db->submit_transaction提交事务写到盘上
再比如以OP_OMAP_RMKEYS(trim pglog的时候就是用到了这个key)为例:1
FileStore::_do_op --> FileStore::_do_transactions --> FileStore::_do_transaction 根据不同的Transaction类型来进行不同的操作 --> case Transaction::OP_OMAP_RMKEYS --> FileStore::_omap_rmkeys --> object_map->rm_keys,后面就是调用到LevelDB里的rm_keys去删除keys。
PGLog封装到transaction里面和journal一起写到盘上的好处:如果osd异常崩溃时,journal写完成了,但是数据有可能没有写到磁盘上,相应的pg log也没有写到leveldb里,这样在osd再启动起来时,就会进行journal replay,这样从journal里就能读出完整的transaction,然后再进行事务的处理,也就是将数据写到盘上,pglog写到leveldb里。
3. PGLog如何参与恢复
PGLog参与恢复主要体现在ceph进行peering的时候建立missing列表来标记过时数据,以便于进行对这些数据进行修复。
故障的OSD重新上线后,PG就会标记为peering状态并暂停处理请求。
- 对于故障OSD所拥有的Primary PG
- 它作为这部分数据”权责”主体,需要发送查询 PG 元数据请求给所有属于该 PG 的 Replicate 角色节点;
- 该 PG 的 Replicate 角色节点实际上在故障 OSD 下线时期间成为了 Primary 角色并维护了“权威”的 PGLog,该 PG 在得到故障 OSD 的 Primary PG 的查询请求后会发送回应;
- Primary PG 通过对比 Replicate PG 发送的元数据和 PG 版本信息后发现处于落后状态,因此它会合并得到的 PGLog并建立“权威” PGLog,同时会建立 missing 列表来标记过时数据;
- Primary PG 在完成“权威” PGLog 的建立后就可以标志自己处于 Active 状态;
- 对于故障OSD所拥有的Replicate PG
- 这时上线后故障 OSD 的 Replicate PG 会得到 Primary PG 的查询请求,发送自己这份“过时”的元数据和 PGLog;
- Primary PG 对比数据后发现该 PG 落后并且过时,比通过 PGLog 建立了 missing 列表;
- Primary PG 标记自己处于 Active 状态;
Peering过程中涉及到PGLog(pg_info和pg_log)的步骤主要包括:
- GetInfo : PG的Primary OSD通过发送消息获取各个Replicate OSD的pg_info信息。在收到各个Replicate OSD的pg_info后,会调用PG::proc_replica_info处理副本OSD的pg_info,在这里面会调用info.history.merge合并Replicate OSD发过来的pg_info信息,合并的原则就是更新为最新的字段(比如last_epoch_started和last_epoch_clean都变成最新的);
- GetLog:根据pg_info的比较,选择一个拥有权威日志的OSD(auth_log_shard) , 如果Primary OSD不是拥有权威日志的OSD,就去该OSD上获取权威日志;
- 选取拥有权威日志的OSD时,遵循3个原则(在find_best_info里):
- Prefer newer last_update
- Prefer longer tail if it brings another info into contiguity
- Prefer current primary
- 也就是说对比各个OSD的pg_info_t,谁的last_update大,就选谁,如果last_update都一样,则谁的log_tail小,就选谁,如果log_tail也一样,就选当前的Primary OSD;
- 如果Primary OSD不是拥有权威日志的OSD,则需要去拥有权威日志的osd上去拉取权威日志,收到权威日志后,会调用proc_master_log将权威日志合并到本地pg log;
- 在merge 权威log到本地pg log的过程中,会将merge的pg_log_entry_t对应的oid和eversion放到missing列表里,这个missing列表里的对象就是Primary OSD所缺失的对象,后续在recovery的时候需要从其他osd pull的。
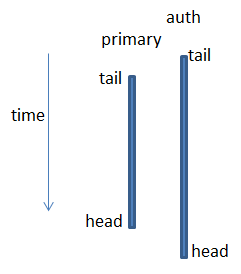
- 选取拥有权威日志的OSD时,遵循3个原则(在find_best_info里):
- GetMissing:拉取其它Replicate OSD 的pg log(或者部分获取,或者全部获取FULL_LOG) , 通过本地的auth log对比,调用proc_replica_log处理日志,会将Replicate OSD里缺失的对象放到peer_missing列表里,以用于后续recovery过程的依据;注意:实际上是在PG:activate里更新peer_missing列表的,在proc_replica_log处理的只是从replica传过来它本地的missing(就是replica重启后根据自身的last_update和last_complete构造的missing列表),一般情况下这个missing列表是空;
4.参考资料
ceph源码v0.80.11版本
《OSD读写流程》http://www.sysnote.org/?p=262
《peering过程》http://blog.csdn.net/changtao381/article/details/49125817
《解析ceph:恢复与数据一致性》http://www.wzxue.com/ceph-recovery/