前段时间一直在研究ceph的快照以及其所涉及的故障恢复逻辑,ceph在这部分的实现挺精妙的,虽然也是基于COW实现的,但是细细品来,其在快照的元数据管理以及父子关系的维护上有独到之处,本文将详细阐述快照的实现原理以及快照对象在恢复时如何至关重要的作用。
1.rbd快照的直观理解
ceph的rbd卷可用做多次快照,每次做完快照后再对卷进行写入时就会触发COW操作,即先拷贝出原数据对象的数据出来生成快照对象,然后对原数据对象进行写入。直观图解如下: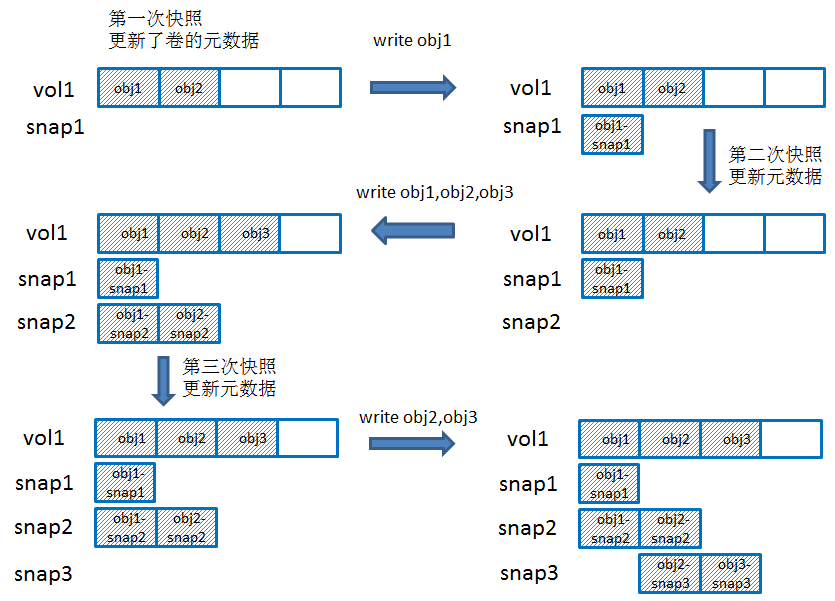
做快照的操作是很快的,因为只更新了卷的元数据,添加了一些快照信息(包括该卷有哪些快照,快照id,如果这个卷是克隆出来的,那么还包括parent信息)。每个rbd卷在rados里都有一个rbd_header对象,这个rbd_header对象里面没数据,卷的元数据都是作为这个对象的属性以omap方式记录到leveldb里(可以使用rados -p
当做完快照后,如果对原卷进行写入的时候,就会先拷贝数据出来生成快照对象(在代码实现里就是一个clone操作),拷贝的时候是整个对象的数据(有可能这个数据对象不是默认的4MB大小,那么有多大拷多大),然后再写入新数据。在ceph里,卷的原对象叫做head对象,而卷作为快照后通过cow拷贝出来的快照对象称为snap对象。
因为ceph里对象是写时分配的,一个新创建的卷如果每一写过数据,在rados里是没有生成数据对象的,只有当数据写入时,才分配出数据对象来。
1)图示中一开始卷就只写了前8MB的数据,也就是只生成了2个数据对象,当做完第一个快照后,更新原数据,再对obj1进行写入前就会拷贝生成obj1-snap1;
2)接着做第二次快照,更新元数据,然后对obj1、obj2、obj3都进行写入,对于obj1,为快照2生成obj1-snap2对象,但是对于obj2就有所不同,因为obj2是做了第二次快照后才要进行修改,也就是说第一次快照和第二次快照之间这个对象的数据没有改变,因此只需要拷贝一次就行了,有两种做法,一种是为较老的快照生成快照对象(这里就是snap1),另外一种做法就是为最新的快照生成快照对象(即snap2)。两种做法都可以,只要记录了引用关系,第一种是snap2引用snap1,而第二种是snap1引用snap2,在ceph里是采用第二种方式来实现的,因此拷贝出obj2-snap2。对于obj3,因为卷原来就没有写过这个对象,所以无需生成快照对象;
3)接着做第三次快照,更新元数据,然后对obj2、obj3进行写入时,生成快照对象obj2-snap3、obj3-snap3;
2.快照关键数据结构
为了便于后续阐述,需要先介绍几个重要的数据结构。
在rbd端,有一个snap相关的数据结构1
2
3
4
5struct SnapContext {
snapid_t seq; // 'time' stamp
vector<snapid_t> snaps; // existent snaps, in descending order
...............
}
其中seq表示最新的快照序号,而snaps保存了这个rbd的所有快照序号。
在librados相关的结构里记录了快照信息。1
2
3
4
5
6struct librados::IoCtxImpl {
......
snapid_t snap_seq;
::SnapContext snapc;
....
}
其中snap_seq的含义:如果是快照,这个snap_seq就是该snap的快照序号;如果不是快照,snap_seq就是CEPH_NOSNAP,在代码里经常看到使用snap_id来判断是否是CEPH_NOSNAP来判断是卷的head对象,还是快照的snap对象。
在OSD端,也即是ceph的服务端,使用SnapSet来保存。1
2
3
4
5
6
7
8
9struct SnapSet {
snapid_t seq;
bool head_exists;
vector<snapid_t> snaps; // descending
vector<snapid_t> clones; // ascending
map<snapid_t, interval_set<uint64_t> > clone_overlap; // overlap w/ next newest
map<snapid_t, uint64_t> clone_size;
......
}
其中
- seq:表示最新快照的序号;
- head_exists:表示head对象是否存在;
- snaps:保存所有的快照序号;
- clones:保存在做完快照后,对原对象进行写入时触发cow进行clone的快照序号,注意并不是每个快照都需要clone对象,从前面的图示中可以看出,只有做完快照后,对相应的对象进行写入操作时才会clone去拷贝数据;
- clone_overlap:为每个做过clone动作的快照,记录在其clone数据对象后,原数据对象上未写过的数据部分,是采用offset~len的方式进行记录的,比如{2=[0~1646592,1650688~12288,1667072~577536]};
- clone_size:表示每次clone的对象的大小,因为有的对象一开始并不是默认的对象大小,比如默认对象大小是4MB,但是一个对象一开始只写了前2MB,所以在做完快照后进行新的写入前,这个对象就是2MB大小;
下面以图示来简单描述快照后对原对象进行写入时的处理:
为了直观理解,clone_overlap采用[startoffset~endoffset]的形式来描述的,实际在代码里实现的时候是采用[offset~len]的形式。
如图示:一个4MB的head对象,在做完快照后第一次写入触发cow,在ceph里就是CLONE操作,就会将这个head对象的数据(可能不是4MB,因为这个head对象没有全部写过一遍)读取出来,拷贝到一个新生成的snap对象里(这个就是snap1的快照对象),然后将新写入的数据(比如256k~512k区间的就是新写入的数据)写到head对象上,并且会更新这个head对象上的clone_overlap[1],一开始这个clone_overlap[1]是整个对象的区间(比如[0~4M]),每次新写入时,就从这个区间里减去写入的区间,比如减去写入了[256k~512k]的数据,得到的clone_overlap[1]的区间就是[0~256k, 512k~4M]。
如果又做了一次快照snap2,然后又新写入数据,比如[2M, 2.25M]区间的数据,同样的,会先clone出snap2的快照对象,也是整个head对象都拷贝,然后写入新的数据到head对象,并且更新clone_overlap[2]为[0~2M, 2.25M~4M]。后续如果继续有新的写入,仍然是将clone_overlap[2]里减去新写入的区间,最后如果这个4MB的对象在快照后都写过一遍后,clone_overlap[2]就会变成空的区间[]。
3.克隆
有了快照后,自然就想从快照恢复出来一个新的卷设备,在ceph里就是克隆卷。
从快照克隆一个卷出来后,在使用这个新卷的时候,在librbd端open的时候就会层层构建出它的父子关系。
在进行I/O请求的处理时就会用到这个父子关系,克隆出的卷在没写入之前因为COW的关系,其数据都是引用的它的父卷和快照的对象。
在ceph的实现中,对于克隆卷的读写,都是先去找这个卷的对象,如果未找到,就再找parent的对象,这样层层往上,直到找到对象为止。应该是先找自己的对象,找不到,再找其所基于的快照的对象,再找不到就找源卷对象(即它的parent),如果这个源卷对象也没有并且它也是从另外一个快照克隆出来的,就会继续往上找。而且这个过程可能涉及到多次librbd与rados的交互,都是通过网络,一旦快照克隆链比较长,效率就很低。而ceph提供克隆卷的flatten的功能,就是先将全部数据都拷贝一份,就可以将链断掉,从而避免去快照或源卷上拿数据,但是flatten本身就是一个比较耗时的操作。
关于ceph librbd的快照也有过不少讨论,王豪迈在《解析ceph:librbd的克隆问题》中提到过两种改进方法。从这个克隆卷的I/O读写流程中可以发现,在OSD端是保存了卷的快照及父子关系的,其实直接在OSD端应该就能够直接找到要读取的对象的,而不用经过多次librbd与rados的交互,当然这只是一个初步的想法,ceph本身已经很复杂了,需要考虑的情况也比较多。
下面结合两个场景来简单说明下。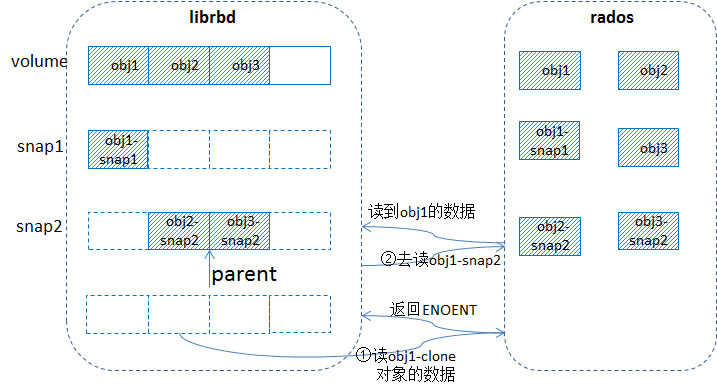
场景1:
1)一个卷写了一部分数据(比如3个对象已写过),然后做了快照snap1,接着对原卷的对象obj1继续写入,触发cow,拷贝出snap1的快照对象obj1-snap1,然后对卷做快照snap2,接着写入obj2和obj3,触发cow,拷贝出snap2的快照对象obj2-snap2, obj3-snap2,然后从snap2克隆出一个卷clone;
2)读克隆卷的数据时,比如读obj1-clone,librbd发送请求到rados,在osd端处理的时候没有找到obj1-clone,返回ENONET给librbd,然后librbd接着去找克隆卷的parent,找到snap2,然后发送请求去读obj1-snap2,在osd端处理的时候根据这个快照id去判断,如果这个快照id比对象上所持有的snapset里的最新的快照id还要新(说明在做完快照2后并没有对obj1进行写入,这样对象obj1的snapset就没有更新),这时如果head对象存在(这里就是obj1)则直接读取head对象(即obj1)的数据;否则就直接返回ENOENT给librbd,librbd端就会构造一个零数据返回给client,这种情况说明源head对象在做快照2之前就不存在。
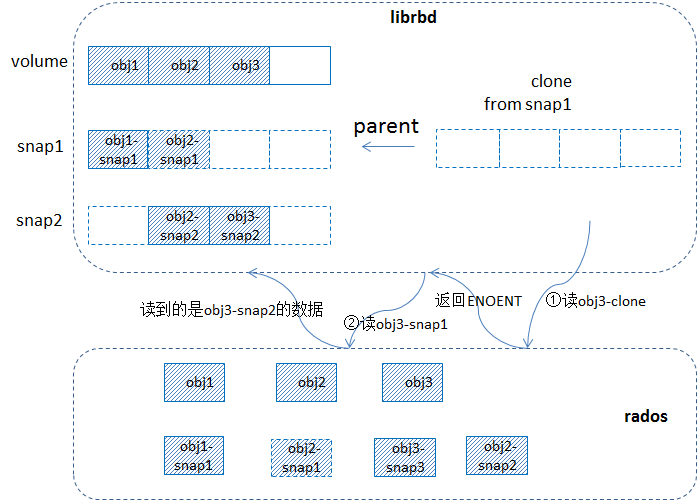
场景2:
1)一个卷写了一部分数据(比如3个对象已写过),然后做了快照snap1,接着对原卷的对象obj1和obj2继续写入,触发cow,拷贝出snap1的快照对象obj1-snap1和obj2-snap1,然后对卷做快照snap2,接着写入obj2和obj3,触发cow,拷贝出snap2的快照对象obj2-snap2, obj3-snap2,然后从snap1克隆出一个卷clone;
2)读取clone卷的数据,比如obj3-clone的时候,发请求到rados,在osd端没有找到该对象,返回ENONENT给librbd,librbd再请求其父对象,就是obj3-snap1,在osd端查找obj3-snap1这个快照对象时,是从snapset的clones里找的,clones里是已经做过cow的快照的id,比如clones=[1,2,3,6,7],那么如果找snapid=2就直接找到了,如果找snapid=4的,那么就找到snapid=6的对象,也就是遍历clones的时候要找到刚好大于等于指定snapid的那个id,这个逻辑是在find_object_context里实现的。这里obj3的clones里是[2],根据snapid=1找的时候就找到了snapid=2的对象。
3)ceph的快照的cow逻辑里的处理是老的快照引用新的快照对象,比如做了2次快照后,再写入数据时触发的cow生成的快照对象的snapid就是最新的id,也就是snapid=2,这样快照1就引用快照2的对象。
从上面两种场景中可以得知,对于一个克隆卷,如果其父卷不是从其他快照克隆出来的,那么对这个克隆卷的读操作时,librbd和osd最多经过两次交互(克隆卷数据对象存在时就直接读取,不存在时就去读其parent的对象,还是读不到就是构造零数据)。但是如果其父卷也是从快照克隆出来的话,就可能存在多于2次的交互。
4.有快照对象的数据恢复
在ceph的基于pglog的数据恢复逻辑里都是与snap对象有所关联的。恢复分为两种:一种是恢复primary上的数据,一种是恢复replica的数据。
在进行恢复的时候,不管是要恢复replica上的还是primary上的都是由primary发起的,要恢复replica的,就是由primary push到replica上;要恢复primary自己的对象,就是从replica pull过来。这两个过程都会由primay先计算出一个对象的data_subsets和clone_subsets,其中data_subsets就是需要通过网络传输过去的数据,而clone_subsets就是可以从本地拷贝的。
为了描述方便,后续的data_subsets和clone_subsets都是采用[startoffset~endoffset]的形式来描述的,实际在代码里实现的时候是采用[offset~len]的形式。
4.1恢复replica
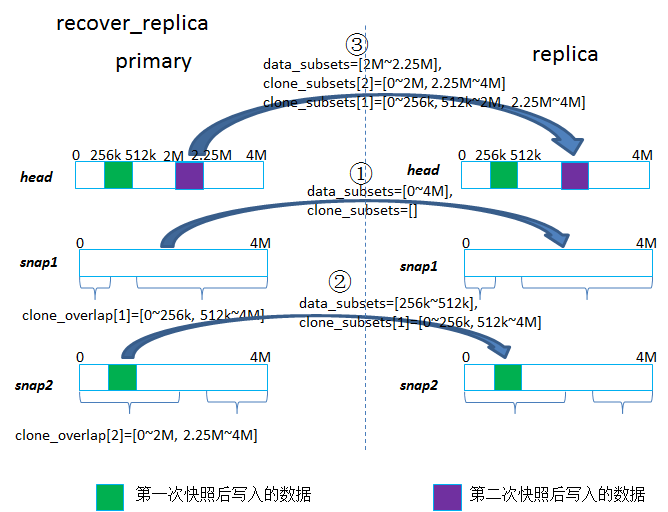
恢复replica时是先恢复snap对象,然后再恢复其head对象。
1)对于snap对象
根据pglog构建出的missing列表的顺序,按照快照对象的新旧,先恢复较老的快照的对象,最后是最新的快照的对象。
- a)如果待恢复的快照对象就是第一次快照后产生的对象,说明它是replica挂掉之后做的快照产生的,这样这个快照对象就需要全量恢复,即{data_subsets=[0, size],clone_subsets=[]},其中size表示当时做快照时,那个head对象的大小,一般head对象都写过一遍后就是4MB;
- b)如果待恢复的快照对象是第n次(n>=2)快照后产生的对象,那么clone_subsets就是根据这个快照的父辈和子孙快照的clone_overlap计算的一个交集,而data_subsets就是用[0~size]减去这个快照父辈和子孙快照的clone_overlap的并集得到的区间(具体计算过程参考源码的calc_clone_subsets函数),比如图示上对于snap2的对象计算得到的就是{data_subsets=[256k~512k], clone_subsets[1]=[0~256k, 512k~4M]};
- c)然后对于一个对象的data_subsets部分,就需要通过网络从primary push过去写到replica的本地,对于clone_subsets就会从replica本地对应的snap对象去clone_range,即在本地将snap1对象的部分数据拷贝给snap2对象;
2)对于head对象
遍历其所有的快照对象,根据这些snap的clone_overlap计算得到的一个交集作为clone_subsets,而data_subsets就是用[0~size]减去这些clone_overlap的并集(具体计算过程参考源码的calc_head_subsets函数),比如图示上对于head对象计算得到的就是{data_subsets=[2M~2.25M], clone_subsets[2]=[0~256k, 512k~4M], clone_subsets[1]=[0~256k, 512k~2M, 2.25M~4M]}。
然后data_subsets的部分,就从本地读出来,push到replica,而clone_subsets的部分就是在replica端从自己本地的snap对象上读取出来拷贝给head对象。
比较奇怪的是,为什么会从多个快照去拷贝数据到head对象,只用最新的那个快照的clone_subset来拷贝到head对象应该就可以了,这个地方还有疑问。
另外,在原来的处理逻辑里是先把replica的head对象删除,然后再结合data_subsets从primary通过网络传输过来的数据,加上clone_subsets从本地snap对象,这样一起来重新构造出head对象,之所以这样做,是因为data_subsets就是根据head对象的各个快照的clone_overlap算出来的,而做快照的时间点与replica挂掉的时间点不一样,也无妨区分是否是replica挂掉的时候做的快照,如果只是用data_subsets那部分数据覆盖写到replica的head对象上(没有先删除replica的head对象),那么replia恢复的head对象就跟primary上的head对象可能不一样,造成数据不一致。
4.2恢复primary
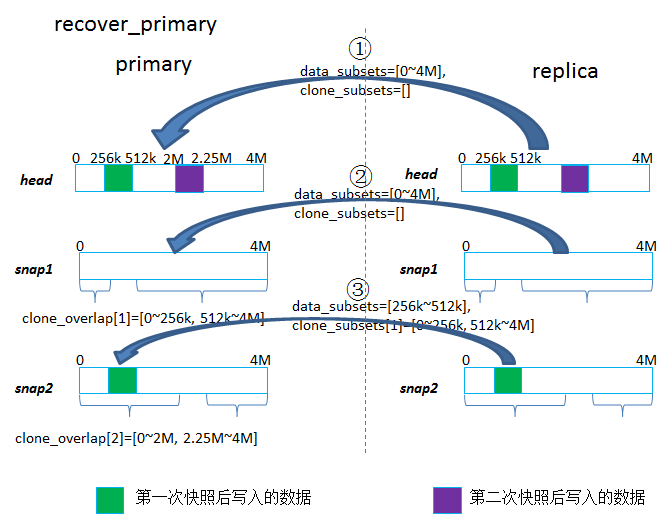
当primary挂掉又起来后进行恢复,先经过peering过程后构建出missing列表,然后由primary进行恢复。
恢复的时候是先恢复head对象,再恢复其snap对象。
1)对于head对象
data_subsets=[0, size],clone_subsets=[]
这里size是head对象大小,一般如果一个对象都写过一遍后就是4MB,也就是说head对象是需要将整个对象的数据通过网络从replica pull过来的。clone_subsets为空,表示没有数据从该primary的本地快照对象拷贝。
这里没有像恢复replica那样去计算data_subsets和clone_subsets,是因为primay挂掉后,可能又做了快照并写入了新数据,这样新产生的快照对象在primay上就没有,而且primary上没有最新的snapset(即里面包含的clone_overlap不是最新的),因此就不能拿来计算,所以直接恢复整个head对象。
2)对于snap对象
与恢复replica一样,根据pglog构建出的missing列表的顺序,按照快照对象的新旧,先恢复较老的快照的对象,最后是最新的快照的对象。
- a)如果待恢复的快照对象就是第一次快照后产生的对象,说明它是primary挂掉之后做的快照产生的,这样这个快照对象就需要全量恢复,即{data_subsets=[0, size],clone_subsets=[]},其中表示当时做快照时,那个head对象的大小,一般head对象都写过一遍后就是4MB;
- b)如果待恢复的快照对象是第n次(n>=2)快照后产生的对象,那么clone_subsets就是根据这个快照的父辈和子孙快照的clone_overlap计算的一个交集,而data_subsets就是用[0~size]减去这个快照父辈和子孙快照的clone_overlap的并集得到的区间(具体计算过程参考源码的calc_clone_subsets函数),比如图示上对于snap2的对象计算得到的就是{data_subsets=[256k~512k], clone_subsets[1]=[0~256k, 512k~4M]};
- c)然后对于一个对象的data_subsets部分,就需要通过网络从replica pull过来写到本地,对于clone_subsets就会从本地对应的snap对象去clone_range,即在本地将snap1对象的部分数据拷贝给snap2对象;
从上面分析得出,恢复replica时是先恢复snap对象,再恢复head对象;而恢复primary时,却是先恢复head对象,再恢复snap对象。这个为什么没有采用一样的逻辑,比如都先恢复snap对象,再恢复head对象,这个地方没有想明白。