1.背景
在对ceph块存储进行性能测试时发现,当有osd重启或者存储机重启时,I/O性能会急剧下降,尤其在随机写的负载下,下降幅度达到90%,并且会持续一段时候才慢慢恢复到正常水平。一开始我们也尝试将恢复相关的参数调低(osd_recovery_max_active=1、osd_recovery_max_chunk=131072、osd_max_backfills=1),以及调整正常I/O和恢复I/O的优先级(osd_recovery_op_priority=10、osd_client_op_priority=63),但是测试结果来看,这些参数的调整没有多大的效果,随机写负载下性能下降仍然很大。
2.原因分析
在《ceph基于pglog的一致性协议》一文中分析了ceph的一致性协议,从中我们得知在osd重启、存储机重启等场景下基于pglog的恢复的时候,在peering的时候会根据pglog来构建出missing列表,然后在恢复时根据missing列表逐个进行恢复,恢复的粒度是整个对象大小(默认4MB,有可能有的对象不足4MB,就按对象大小),即使只修改了一个4KB,也需要将4MB的对象拷贝过来,这样100个io就会达到400MB的带宽,对网络及磁盘产生较大的影响。当写io命中正在修复的对象时,也是先修复原来4MB的对象,即需要将4MB的数据通过网络拷贝过来,延迟就会增加很多,然后再写入数据,对于随机写的场景尤其严重,基本都是命中的情况,带来相当大的延迟,从而iops下降(下降幅度80%~90%)。这个影响时间取决于上层的业务量和osd停服的时间。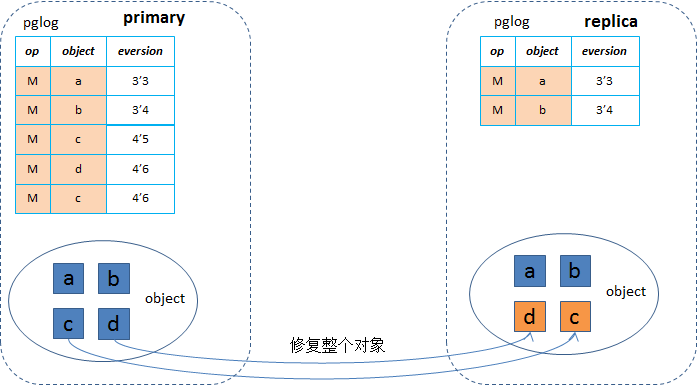
3.恢复优化
因为pglog里每条记录里只是记了操作及版本等信息,并没有记录这次操作是修改哪部分数据,所以优化的办法就是在pglog里记录每次操作修改的区间,记为[offset,len](实现时pglog结构里引入dirty_extents来表示),正常写I/O处理时,会写pglog,对应的是一个MODIFY操作,在这条记录里记上修改的区间。
当一个osd故障重启后,进行peering的时候,合并pglog来构建missing列表时就可以将同一个对象的多次修改的[offset,len]求一个并集,得出故障期间总的修改区间,然后在恢复的时候就能够根据这个范围来恢复这部分增量数据,从而大幅度减少了恢复时的网络和磁盘带宽,以及正常I/O命中恢复对象的等待时间,从而大幅降低对正常I/O的性能影响(尤其是对于随机写I/O的场景)。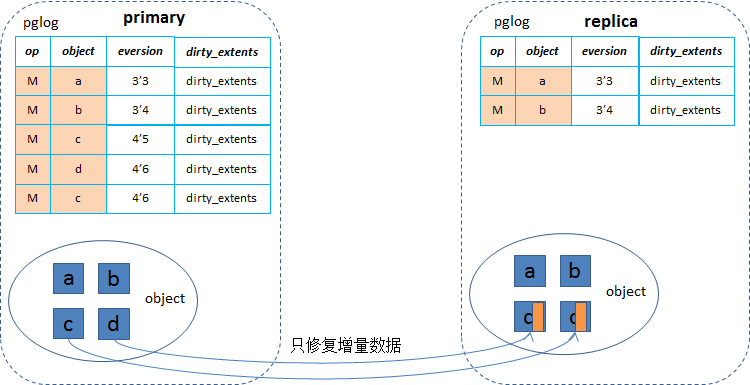
针对我们使用的块存储的应用场景,为了减小实现的复杂度,引入一个标记can_recover_partial来表示是否可以进行部分恢复,默认是false,当进行写I/O的处理时记录pglog里的[offset,len],并且标记can_recover_partial为true,然后恢复时就可以根据这个标记只恢复对象内的增量数据。对于无法判断是否可以进行部分优化时,就回退到原有的恢复逻辑去恢复整个对象,需要考虑几种情况,包括:truncate、omap、clone、EC等。
truncate
truncate的操作对应的就是截断对象,可以类比于文件系统里的ftruncate的操作(可以将文件截断,或者将文件扩大)。原生ceph的pglog没有TRUNCATE的操作码,它里面的truncate操作都是MODIFY操作,如果一个对象先被修改了,然后又被truncate了,那么在恢复这个对象的时候仍然是按照这整个对象来恢复,有可能因为truncate这个对象变小了(小于4MB),这个不用管, 直接将这个对象读出来拷贝过去就行了。
但是我们要在pglog里加入[offset, len]来表示修改范围,那么和truncate混在一起后,就需要做区分,为了简单起见,当碰到truncate操作时,将can_recover_partial设置成false,这样truncate的处理就跟原来一样,在我们的使用场景下,trucate操作不常见。
omap
omap即objectmap,用来记录对象的扩展属性,因为文件系统的xatrr属性数量及长度都有限制,超过了就需要放到omap中。设置omap属性时,对应到pglog里也是一个MODIFY操作,也就是说omap在多副本间的一 致性也是由pglog来保证的。在恢复的时候合并pglog来构建missing对象时,是不区分属性还是数据,都认为是对这个对象的修改,在恢复的时候都是先恢复恢复属性(xatrr和omap),然后再恢复数据。这样的话,即使一个对象在pglog里只设置了属性,在恢复的时候会连数据一起恢复过来,也即是多了一次数据的拷贝。在块存储的场景下,这个代价是可以接受的,因此不必针对omap做特殊处理。
clone
这里的clone指的clone对象操作,就是做了快照之后对原卷进行写入时触发的cow操作。每次clone操作会在pglog里记录一条CLONE的记录,然后在filestore里会根据这个CLONE操作进行clone_range的处理,也就是从原来的head对象(表示卷的数据对象),拷贝数据到新生成的snap对象(即快照的对象)。在peering的时候合并pglog时,没有区分MODIFY和CLONE的,都会构建丢失对象放到missing列表里,也就是说这个missing列表里有可能既包含head对象,也包含snap对象。
在《ceph rbd快照原理解析》里详细介绍了快照的实现及故障恢复的处理,引入恢复优化后,对于snap对象还是按照原来的逻辑处理,而对于head对象就要做不同处理,按照对象的修改区间来进行恢复。
EC
块存储下都是采用多副本的策略,而不会用到纠删码(EC),一般是ceph对象存储里才用到纠删码,因此我们不考虑这种情况,遇到纠删码相关的就就按照原有的逻辑进行恢复。
4.优化效果
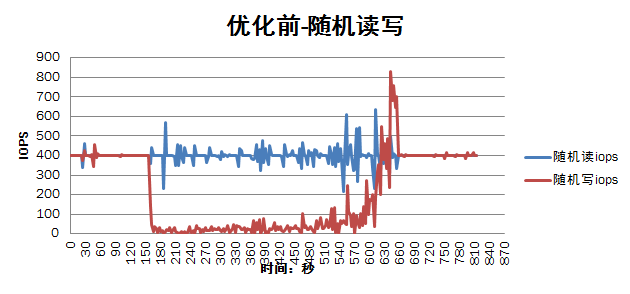
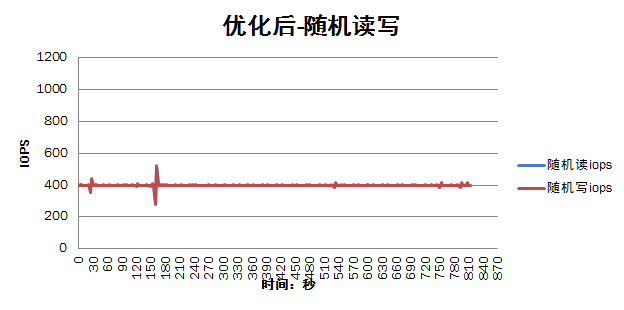
下面的测试结果对比了优化前和优化后的性能(主要针对随机读写的场景),从结果上来看,效果显著:
1)减少了重启osd过程中对集群正常存储I/O性能影响,从优化前的I/O性能下降90%到优化后I/O性能只下降10%;
2)缩短重启恢复所需要的时间,重启单个osd的恢复时间从10分钟减少到40秒左右;