最近测试ceph恢复的时候对业务io的影响,发现修复时ceph集群的性能骤降,比如正常情况下一个卷的随机4k写的iops约10k,但是恢复的时候骤降到1k左右。从ceph设计来说,恢复涉及到peering,backfill,remap等操作,对性能必然会存在影响,这里先不深究ceph的恢复机制,后续研究清楚了再进行分析,本文以重启osd为例,从现象入手来简要分析重启osd对ceph性能的影响。
1.环境配置
1)硬件配置:使用openstack + ceph后端,计算和存储分离,6台物理机作为ceph存储节点,每台机器6块ssd,每块ssd上运行一个osd(其中journal和data各占一个分区),整个集群的数据流使用万兆网络;
2)测试时在6台kvm虚拟机里分别挂载一块20GB的ceph块设备,然后使用fio分别跑6种I/O模型:4KB块大小的随机写,4KB块大小的随机读,4KB块大小的随机混合读写(1:1比例),64KB块大小的顺序写,64KB块大小的顺序读,64KB块大小的顺序混合读写(1:1比例)。使用这样的模型来模拟集群负载;
2.重启osd进行测试
1)先将6个卷的I/O跑起来,然后重启一个osd;
2)观察到随机写的iops从10k降到低于1k,并且波动还比较大,随机读的iops从10k降到几百;
3)性能下降持续了10几秒后又正常,是因为恢复完了;
3.性能排查分析
3.1使用ceph osd perf查看重启osd过程中的osd的性能数据
1 | #ceph osd perf |
可以看到这个osd的commit_latency和apply_latency都增加了很多(从正常的几ms升高到几百ms),其中commit_latency是值写journal完成的时间,apply_latency是写到osd的buffer cache里完成的时间。
这个osd在重启后进行恢复的时候写journal延迟升高,导致了上层写性能的下降,那就从这个点入手去进行排查。
3.2 fs_commit_latency的计算
既然恢复的时候fs_commit_latency增加,那么就先看下这个时间是怎么计算出来的。
在代码里搜索fs_commit_latency找到如下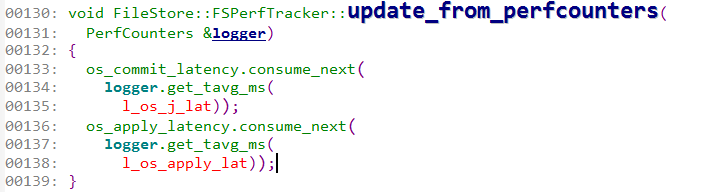
因此只要找出l_os_j_lat是怎么计算的。在queue_completions_thru里计算的这个值,而开始时间是从completion_item里得到的,也就是在submit_entry里记的开始时间。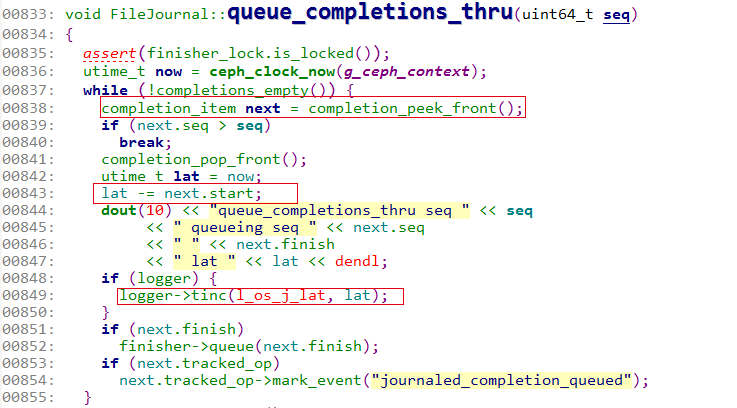
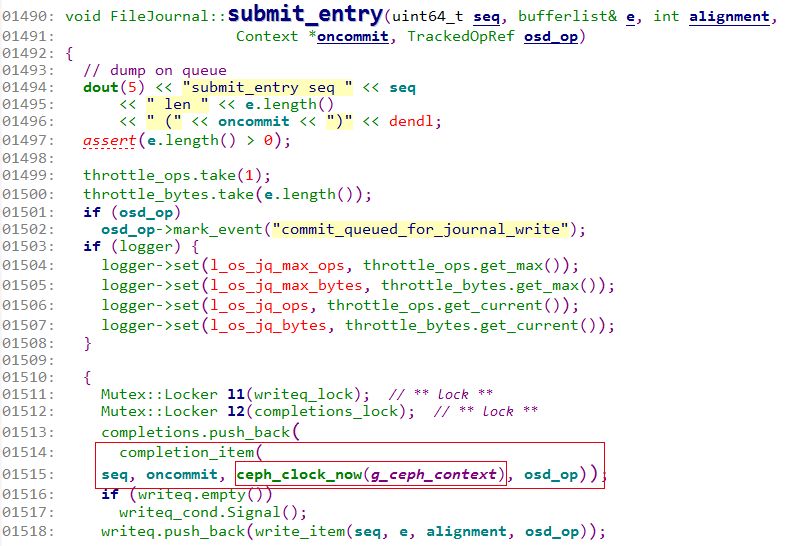
从我之前的博客里《OSD读写流程(2)–主OSD写操作事务的处理》里可以看到,l_os_j_lat就是统计的放入writeq到写journal完成的时间。这个时间既是ceph osd perf里看到的fs_commit_latency,也是ceph daemon osd.x perf dump里看到的journal_latency。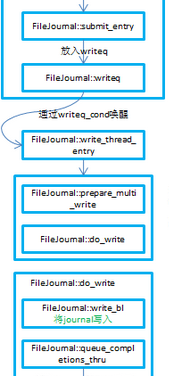
3.3 结合日志分析
从代码逻辑上看就是放到writeq后然后唤醒journal线程去写journal,这里面可能在什么地方耗时比较多呢?为此,将这个journal的日志打开,从日志里看看有没有线索。
1)修改ceph.conf,加入debug_journal=20,来开启journal的debug日志,然后重启osd再进行测试,就可以在/var/log/ceph/ceph-osd.56.log里看到journal相关的debug日志了。
2)使用ceph -w观察重启osd间恢复的情况,将恢复的时间区间找出来,比如恢复的时间2015-12-02 09:47:33~2015-12-02 09:47:33,那么就根据时间戳从ceph-osd.56.log里将这个时间段的journal日志grep出来。
3)根据之前的代码看到queue_completions_thru里会打印出l_os_j_lat,那就根据关键字”queue_completions_thru”到刚才截取的日志里搜索,grep出来,然后查看这个lat的变化趋势,看看是否有明显升高的情况,
结果确实发现有明显增加的情况:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
362015-12-02 09:47:34.097848 7f87bfdf3700 10 journal queue_completions_thru seq 143576679 queueing seq 143576679 0x3f14420 lat 0.000690
2015-12-02 09:47:34.099863 7f87bfdf3700 10 journal queue_completions_thru seq 143576680 queueing seq 143576680 0x1a69edb0 lat 0.000875
2015-12-02 09:47:34.100190 7f87bfdf3700 10 journal queue_completions_thru seq 143576681 queueing seq 143576681 0x8ad0000 lat 0.000227
2015-12-02 09:47:34.101104 7f87bfdf3700 10 journal queue_completions_thru seq 143576682 queueing seq 143576682 0x8ad1860 lat 0.000543
...............................
2015-12-02 09:47:34.221383 7f87bfdf3700 10 journal queue_completions_thru seq 143576896 queueing seq 143576872 0x1c18f560 lat 0.012914
2015-12-02 09:47:34.221390 7f87bfdf3700 10 journal queue_completions_thru seq 143576896 queueing seq 143576873 0x1c18f710 lat 0.012867
2015-12-02 09:47:34.221392 7f87bfdf3700 10 journal queue_completions_thru seq 143576896 queueing seq 143576874 0x1bb212f0 lat 0.012765
2015-12-02 09:47:34.221395 7f87bfdf3700 10 journal queue_completions_thru seq 143576896 queueing seq 143576875 0x1c18ecf0 lat 0.012647
2015-12-02 09:47:34.221397 7f87bfdf3700 10 journal queue_completions_thru seq 143576896 queueing seq 143576876 0x1bb21290 lat 0.012532
...............................
2015-12-02 09:47:34.689892 7f87bfdf3700 10 journal queue_completions_thru seq 143577160 queueing seq 143577159 0x189a4270 lat 0.089205
2015-12-02 09:47:34.689896 7f87bfdf3700 10 journal queue_completions_thru seq 143577160 queueing seq 143577160 0x2a1ddd0 lat 0.088614
2015-12-02 09:47:34.730755 7f87bfdf3700 10 journal queue_completions_thru seq 143577163 queueing seq 143577161 0x1aff0b40 lat 0.129044
2015-12-02 09:47:34.730765 7f87bfdf3700 10 journal queue_completions_thru seq 143577163 queueing seq 143577162 0x2a37170 lat 0.129024
2015-12-02 09:47:34.730769 7f87bfdf3700 10 journal queue_completions_thru seq 143577163 queueing seq 143577163 0x1a3ca930 lat 0.128522
2015-12-02 09:47:34.746175 7f87bfdf3700 10 journal queue_completions_thru seq 143577166 queueing seq 143577164 0x1a59cdb0 lat 0.142385
...............................
2015-12-02 09:47:34.808426 7f87bfdf3700 10 journal queue_completions_thru seq 143577236 queueing seq 143577221 0x1a6696b0 lat 0.013378
2015-12-02 09:47:34.808429 7f87bfdf3700 10 journal queue_completions_thru seq 143577236 queueing seq 143577222 0x1a669830 lat 0.013349
2015-12-02 09:47:34.808431 7f87bfdf3700 10 journal queue_completions_thru seq 143577236 queueing seq 143577223 0x1bb21500 lat 0.013290
2015-12-02 09:47:34.808434 7f87bfdf3700 10 journal queue_completions_thru seq 143577236 queueing seq 143577224 0x1a669770 lat 0.013255
2015-12-02 09:47:34.808436 7f87bfdf3700 10 journal queue_completions_thru seq 143577236 queueing seq 143577225 0x1a685c80 lat 0.013229
2015-12-02 09:47:34.808438 7f87bfdf3700 10 journal queue_completions_thru seq 143577236 queueing seq 143577226 0x1cf00450 lat 0.008882
2015-12-02 09:47:34.808445 7f87bfdf3700 10 journal queue_completions_thru seq 143577236 queueing seq 143577227 0x1a59c720 lat 0.006527
...............................
2015-12-02 09:47:36.367197 7f87bfdf3700 10 journal queue_completions_thru seq 143577901 queueing seq 143577901 0x1cdcb560 lat 0.402130
2015-12-02 09:47:36.405384 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577902 0x1a4cf890 lat 0.440091
2015-12-02 09:47:36.405392 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577903 0x2b230090 lat 0.439959
2015-12-02 09:47:36.405395 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577904 0x1cf01d70 lat 0.439845
2015-12-02 09:47:36.405398 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577905 0x1cc5ff20 lat 0.439770
.................................
2015-12-02 09:48:05.289463 7f87bfdf3700 10 journal queue_completions_thru seq 143597534 queueing seq 143597533 0x1880c630 lat 0.001408
2015-12-02 09:48:05.289479 7f87bfdf3700 10 journal queue_completions_thru seq 143597534 queueing seq 143597534 0x18981440 lat 0.000517
2015-12-02 09:48:05.290794 7f87bfdf3700 10 journal queue_completions_thru seq 143597535 queueing seq 143597535 0x1523a330 lat 0.000571
2015-12-02 09:48:05.291299 7f87bfdf3700 10 journal queue_completions_thru seq 143597536 queueing seq 143597536 0x16aabc50 lat 0.000384
latency在变化,逐渐增加到几百ms,而且还是波动的,直到修复结束后,又降低到正常的0.几ms。
4)根据日志及代码都可以知道写journal的每一个写io都有一个seq,并且是严格递增的,写的顺序也是按照先写seq序号小的,再写seq序号大的。既然如此,那就根据seq序号去日志里看看延迟高的那个io的log信息,以“seq 143577921”为例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
362015-12-02 09:47:36.076975 7f87c05f4700 15 journal prepare_single_write 1 will write 5234556928 : seq 143577880 len 4196270 -> 4202496 (head 40 pre_pad 3434 ebl 4196270 post_pad 2712 tail 40) (ebl alignment 3474)
2015-12-02 09:47:36.077003 7f87bb5ea700 10 journal op_apply_finish 143577875 open_ops 5 -> 4, max_applied_seq 143577874 -> 143577875
2015-12-02 09:47:36.077024 7f87a6743700 10 journal op_submit_start 143577921
2015-12-02 09:47:36.077032 7f87a6743700 10 journal op_journal_transactions 143577921 0x1b9e7440
2015-12-02 09:47:36.077040 7f87a6743700 5 journal submit_entry seq 143577921 len 4196270 (0x1a4e1e00)
2015-12-02 09:47:36.077047 7f87a6743700 10 journal op_submit_finish 143577921
..................
2015-12-02 09:47:36.368799 7f87c05f4700 15 journal prepare_single_write 20 will write 5319761920 : seq 143577921 len 4196270 -> 4202496 (head 40 pre_pad 3434 ebl 4196270 post_pad 2712 tail 40) (ebl alignment 3474)
..................
2015-12-02 09:47:36.373188 7f87c05f4700 20 journal write_aio_bl 5311217664~12746752 seq 143577921
..................
2015-12-02 09:47:36.405376 7f87bfdf3700 20 journal check_aio_completion completed seq 143577921 5311217664~12746752
2015-12-02 09:47:36.405381 7f87bfdf3700 20 journal check_aio_completion queueing finishers through seq 143577921
2015-12-02 09:47:36.405384 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577902 0x1a4cf890 lat 0.440091
2015-12-02 09:47:36.405392 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577903 0x2b230090 lat 0.439959
2015-12-02 09:47:36.405395 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577904 0x1cf01d70 lat 0.439845
2015-12-02 09:47:36.405398 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577905 0x1cc5ff20 lat 0.439770
2015-12-02 09:47:36.405401 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577906 0x1c0c9530 lat 0.373900
2015-12-02 09:47:36.405403 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577907 0x1983f8c0 lat 0.373753
2015-12-02 09:47:36.405405 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577908 0x1c0c9500 lat 0.373637
2015-12-02 09:47:36.405408 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577909 0x50cfb890 lat 0.373515
2015-12-02 09:47:36.405426 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577910 0x1c177950 lat 0.373398
2015-12-02 09:47:36.405430 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577911 0x1c36aba0 lat 0.373152
2015-12-02 09:47:36.405434 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577912 0x8ad0360 lat 0.373025
2015-12-02 09:47:36.405437 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577913 0x1cb3cd50 lat 0.372915
2015-12-02 09:47:36.405438 7f87b8383700 10 journal op_apply_start 143577902 open_ops 0 -> 1
2015-12-02 09:47:36.405441 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577914 0x4707e630 lat 0.372819
2015-12-02 09:47:36.405445 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577915 0x1a4e07b0 lat 0.372727
2015-12-02 09:47:36.405448 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577916 0x1c0d0a50 lat 0.372623
2015-12-02 09:47:36.405452 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577917 0x1bafe8a0 lat 0.372516
2015-12-02 09:47:36.405455 7f87b637f700 10 journal op_apply_start 143577906 open_ops 1 -> 2
2015-12-02 09:47:36.405459 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577918 0x1b3528d0 lat 0.372410
2015-12-02 09:47:36.405464 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577919 0x1c0c8cc0 lat 0.372320
2015-12-02 09:47:36.405468 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577920 0x1a1e59e0 lat 0.370506
2015-12-02 09:47:36.405471 7f87bfdf3700 10 journal queue_completions_thru seq 143577921 queueing seq 143577921 0x1a4e1e00 lat 0.328340
....................
从上面的日志来看seq 143577921这个io在submit_entry开始的时间是09:47:36.077040,而一直到09:47:36.405471才最后完成,
而且比较明显的是这个io提交到writeq的时间点是2015-12-02 09:47:36.077040。1
2015-12-02 09:47:36.077040 7f87a6743700 5 journal submit_entry seq 143577921 len 4196270 (0x1a4e1e00)
而真正轮到这个io处理的时间点是2015-12-02 09:47:36.368799,从放到writeq到开始prepare这个io就已经过了约300ms了。1
2015-12-02 09:47:36.368799 7f87c05f4700 15 journal prepare_single_write 20 will write 5319761920 : seq 143577921 len 4196270 -> 4202496 (head 40 pre_pad 3434 ebl 4196270 post_pad 2712 tail 40) (ebl alignment 3474)
而且从上面的日志中还看到journal线程并不是空闲的,它还在处理队列里前面的io,大致可以算出writeq里还有143577921-143577880=41个io。1
2015-12-02 09:47:36.076975 7f87c05f4700 15 journal prepare_single_write 1 will write 5234556928 : seq 143577880 len 4196270 -> 4202496 (head 40 pre_pad 3434 ebl 4196270 post_pad 2712 tail 40) (ebl alignment 3474)
3.4从这些现象来看,有2处怀疑点:
a)一个是journal线程里有提交数据量或者io数的限制;
b)后端磁盘慢了,io处理不过来导致io堆积,从而影响上层io;
1)对于第一个怀疑点,从代码上看,在write_thread_entry是prepare_multi_write,在prepare_multi_write里循环调用prepare_single_write,大致的意思就是写journal时会将从队列里取多个io拼在一起,放到bufferlist里,然后再下发到后端设备。在拼io的时候并不是一个劲地往bufferlist里放,而是有限制的,取决于两个参数:
journal_max_write_bytes:journal一次性写入的最大字节数,默认值是10MB
journal_max_write_entries:journal一次性写入的最大记录数(即往bufferlist放的最大io数),默认值是100
并且从日志里也看到有超过journal_max_write_bytes的打印日志。1
2015-12-02 09:47:36.079302 7f87c05f4700 20 journal prepare_multi_write hit max write size 10485760
因此尝试将这个值改大成100MB再试试(调整这个参数需要谨慎,因为调大了对磁盘的io压力也增大了),从fio的结果来看,还是性能骤降,影响还是跟之前一样,不过从osd的日志里看到写journal的latency最大的是100多ms,比之前的300多ms降低了一些,说明改了这个参数有一点效果,但是效果不明显,然并卵。
这样看来,就很有可能是第二个怀疑点,也就是后端磁盘慢了导致的。使用iostat观察重启osd期间这个osd所在磁盘的io情况。其中sdu1是osd的数据盘,sdu2是osd的journal盘。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdu 0.00 0.00 0.00 666.00 0.00 157.04 482.90 145.09 210.28 0.00 210.28 1.50 100.00
sdu1 0.00 0.00 0.00 638.00 0.00 156.08 501.02 143.48 216.92 0.00 216.92 1.57 100.00
sdu2 0.00 0.00 0.00 7.00 0.00 0.96 280.00 1.41 208.00 0.00 208.00 114.29 80.00
avg-cpu: %user %nice %system %iowait %steal %idle
4.96 0.00 4.87 4.03 0.00 86.14
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdu 0.00 0.00 0.00 636.00 0.00 156.46 503.81 177.52 259.62 0.00 259.62 1.57 100.00
sdu1 0.00 0.00 0.00 528.00 0.00 137.25 532.38 145.96 272.19 0.00 272.19 1.89 100.00
sdu2 0.00 0.00 0.00 72.00 0.00 19.20 546.22 31.45 295.78 0.00 295.78 12.17 87.60
avg-cpu: %user %nice %system %iowait %steal %idle
7.03 0.00 4.77 3.58 0.00 84.63
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdu 0.00 0.00 0.00 842.00 0.00 154.83 376.58 117.44 174.29 0.00 174.29 1.18 99.60
sdu1 0.00 0.00 0.00 419.00 0.00 81.99 400.73 92.50 269.19 0.00 269.19 2.35 98.40
sdu2 0.00 0.00 0.00 269.00 0.00 72.84 554.56 24.59 124.94 0.00 124.94 3.06 82.40
正常情况下的数据盘和日志盘上的io都不算大,至少带宽不带,而且都是小io,当进行恢复时,数据盘上的io一下子上去了,都是大块io,然后影响了日志盘的io(因为数据盘和日志盘各占一个分区),这样写journal慢了,那么就会慢慢堆积,一次提交多个(正常的情况下写journal一般就一次一个),一下子日志盘上也变成了大块顺序io,这样数据盘和日志盘的相互影响下,延迟很高,写journal这么高的延迟导致写io堆积变慢,上层iops自然就降低了。
2)为了证实上面的猜测,将这个osd的data盘和journal盘分开,各单独占一块ssd,然后再进行重启osd的测试,发现对写的影响很小了,
ceph osd perf没有发现osd的commit_latency没有明显的升高,iostat查看的结果也表明journal盘上没有瓶颈了,也就是证实了上面的猜测,恢复的时候写data盘影响了写journal的io。(ps:不过我们用的时候不会将osd的data盘和journal盘分别放到不同的ssd上,这样成本太高了。)
3)另外,针对ssd本身的性能进行测试,也是分两个分区,模拟恢复时的io情况,对一个分区进行随机大块写,对另外一个分区进行顺序大块写,得到的结果如下,说明这块ssd本身在这种io模式下延迟就很高了,而且队列深度很大,说明压力确实很高,ssd也撑不住。1
2
3
4
5
6
7
8
9
10
11
12
13Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdu1 0.00 0.00 0.00 422.00 0.00 105.50 512.00 48.58 117.91 0.00 117.91 2.37 100.00
sdu2 0.00 0.00 0.00 256.00 0.00 46.88 375.00 31.96 116.92 0.00 116.92 3.91 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
1.93 0.00 3.04 6.28 0.00 88.75
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdu1 0.00 0.00 0.00 395.00 0.00 98.75 512.00 48.34 119.68 0.00 119.68 2.53 100.00
sdu3 0.00 0.00 0.00 280.00 0.00 52.25 382.17 31.98 120.26 0.00 120.26 3.57 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
3.39 0.00 3.99 5.63 0.00 86.99
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdu1 0.00 0.00 0.00 407.00 0.00 101.77 512.12 46.86 118.06 0.00 118.06 2.46 100.00
sdu2 28.00 0.00 4.00 166.00 0.02 31.87 384.19 22.00 137.15 72.00 138.72 5.86 99.60
4)而对于新的ssd也进行了类似的测试,结果要好一些,延迟才几十ms.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdc 0.00 0.00 0.00 2445.00 0.00 553.62 463.73 79.92 32.40 0.00 32.40 0.41 100.00
sdc1 0.00 0.00 0.00 1481.00 0.00 370.25 512.00 47.95 32.40 0.00 32.40 0.68 100.00
sdc2 0.00 0.00 0.00 964.00 0.00 183.38 389.58 31.97 32.39 0.00 32.39 1.04 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.04 0.00 0.04 10.33 0.00 89.59
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdc 0.00 0.00 0.00 2524.00 0.00 570.25 462.71 79.95 31.86 0.00 31.86 0.40 100.00
sdc1 0.00 0.00 0.00 1504.00 0.00 376.00 512.00 47.98 31.86 0.00 31.86 0.66 100.00
sdc2 0.00 0.00 0.00 1020.00 0.00 194.25 390.02 31.97 31.85 0.00 31.85 0.98 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.04 0.00 0.17 11.13 0.00 88.66
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdc 0.00 0.00 0.00 2505.00 0.00 563.00 460.29 79.94 31.71 0.00 31.71 0.40 100.00
sdc1 0.00 0.00 0.00 1513.00 0.00 378.25 512.00 47.95 31.71 0.00 31.71 0.66 100.00
sdc2 0.00 0.00 0.00 992.00 0.00 184.75 381.42 31.98 31.73 0.00 31.73 1.01 100.00
5)事实上,从代码上来看,在journal的write thread里有限制aio的机制来避免对磁盘带来过大的压力,因为一个劲地往磁盘下发io,磁盘也有处理极限,超过处理能力只会让后续的io更慢,还不如在队列里等着。
从日志里也能看到限制aio时的log。1
22015-12-02 09:47:36.084964 7f87c05f4700 20 journal write_thread_entry aio throttle: aio num 1 bytes 12607488 ... exp 2 min_new 4 ... pending 0
2015-12-02 09:47:36.084967 7f87c05f4700 20 journal write_thread_entry deferring until more aios complete: 1 aios with 12607488 bytes needs 4 bytes to start a new aio (currently 0 pending)
3.5 调整恢复的参数
从上面的分析看来,本质上的影响还是由于恢复导致的,那么就控制恢复的速度来减小对正常io的影响。修改下面几个参数:1
2
3
4#ceph tell osd.* injectargs '--osd_recovery_threads 1'
#ceph tell osd.* injectargs '--osd_max_backfills 1'
#ceph tell osd.* injectargs '--osd_recovery_max_active 1'
#ceph tell osd.* injectargs '--osd_recovery_max_chunk 16777216'
然后再进行重启osd的恢复测试,发现效果不明显,对正常io的影响仍然很大。而且这个影响还是全局的,基本上会影响到所有的ceph块设备,影响大小及时间取决于io的压力及修复的数据量。