花瓣系统是一个分布式虚拟盘,具有如下特点:
- 单盘支持2^64 byte 的存储空间;
- 无单点
- 在线扩展(新增server和disk)
- 按需分配空间
- load balance
- 支持备份和恢复,快照。
系统概貌
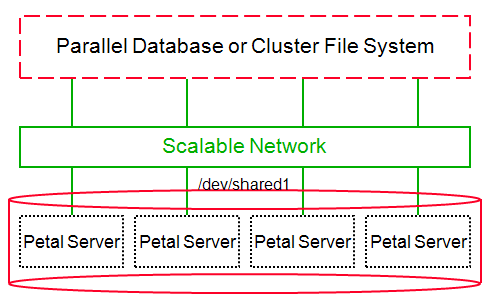
petal使用rpc调用访问虚拟盘,全局的状态在每台server里都有记录,通过paxos协议确保一致,clients保存少量的映射信息来决定请求分发到哪台服务器,如果这样请求失败,服务器会返回error,然后client更新映射,并且重试请求。petal server modules
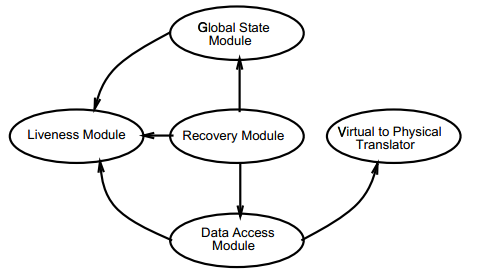
- liveness module:类似于心跳,确保系统中各个服务器的存活状态。互相发的信息类似“I’am alive”,“You’re alive”
- global state module:维护系统中服务器成员信息,基于Paxos或者”part-time parliament”算法,并且保证管理操作(如创建,删除,快照,添加删除机器)是容错的。
- data access module和revoery module:控制数据的分布与存储,目前支持无副本的条带和chained-declustering两种。
- virtual to physical translator:逻辑地址到物理磁盘地址的映射。
virtual to physical translation
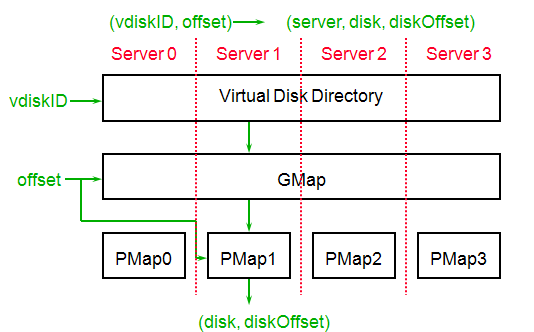
VDir和GMap在每台server上都保存有,然后每台server本地保存一份PMap
映射的步骤:
1)根据VDir把vdiskID找到对应的GMap
2)根据GMap得到serverID
3)指定的server根据PMap把GMapID和offset转换成disk和diskOffset
为了减少通信的开销,执行第二步和第三步的服务器通常是一个,所以一个客户端发送请求到一台服务器,这台服务器就能执行以上的三步,而无需跟其他服务器通信。
每个vdisk都有一个GMap,保存了这个vdisk分布的服务器和冗余策略,为了容错一个server的出错,可以指定一台备server,映射同样的offset,当主server不可用时,备server就可以服务。
GMap不能修改,如果要改变一个vdisk分布的服务器或者冗余策略,就需要为这个vdisk重新指定一个新的GMap。
PMap是把虚拟地址转换成磁盘和对应的偏移,类似于虚拟内存的页表,每个PMap entry映射物理磁盘的64KB空间,进行整个翻译映射操作的服务器同时就是最后执行这个请求(读写对应物理盘)的服务器。
全局映射和物理映射的分离使得能够保存一些信息在本地,这样就会减少服务器间需要通信的全局信息。
支持备份
cow的快照,只读
支持快照后,上面描述的映射过程就有所修改。
在上面的第一步中就不是直接得到一个GMap,而是得到一个
最后PMap就会根据
当对一个vdisk创建快照时,在VDir中就会生成一个新的版本,比如
而原来的epoch就被刚创建的快照使用了。这样对vdisk新写的数据都会使用新的版本号创建新的entry,而不是覆盖原来的。
并且读请求能够根据最近的版本找到最近写的数据。
对于应用来说,创建一个快照需要不到1s时间的暂停。
另一种不需要中断应用的方式就是创建一个“crash-consistent”的快照,这个一般用于应用崩溃的时候恢复使用。
Incremental Reconfiguration
在线扩展
新加磁盘由server自己处理,下次创建的vdisk就会把新的disk考虑进去,不过为了负载均衡,也可以使用后台程序进行重平衡。
新增server
首先新的server加到集群中,然后liveness module把新加进来的server放到server sets中,最后已经存在的vdisks reconfigured
reconfiguration的过程:
1)使用新的冗余策略和服务器映射表创建新的GMap
2)将所有的vdisk的VDir指向新的GMap
3)根据新的GMap重新分布数据
难点之处在于在线重分布,并且不能对现有正常的访问造成较大的影响。
为此设计了reconfiguration的算法,分为两步,首先就基本算法,然后是改进的算法。
基本算法中,也是先要执行上述的第一和第二步,
然后,从最新的版本并且还未移动的数据开始,因为有大量的数据需要移动,花费的时间较长,在此期间,仍然要处理正常的请求。
对于正常的读请求,如果在new GMap中没有找到对应的映射,则从old GMap中重试。
对于写请求,只从new GMap访问。
因为从最新的版本开始移动数据,确保了不会从较低版本读取到数据。
基本算法有个缺点在于,整个vdisk的映射表在数据移动前都已经改变(有的只是部分改变),那这样读请求到new GMap都会失败,并且都从old GMap去重试,这就带来较大的通信开销,并且可能降低系统性能。
改进的算法:
将vdisk的空间划分成三部分:old,new和fenced
请求到old或者new空间的请求就直接从old和new GMap中查找。
对于fenced区域,使用基本算法来进行处理,一旦一段fenced区域的数据都已经移走了,那么这段区域就变成new了,然后接着就fence old区域的另外部分。
重复这个过程直到所有的old变成new。
一般fenced区域的大小为1%~10%整个vdisk空间,这样有效减小了开销。
并且为了防止一段连续区域因此带来的高负荷,在选取fenced区域时,使用非连续的区域来组成fenced区域,而不是一整段连续区域。
Data Access And Recovery
采用chained-declustering的数据放置策略。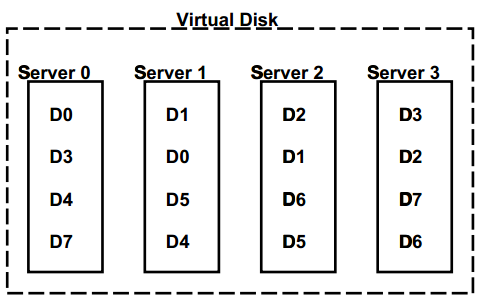
好处在于无单点,一台服务器坏了,还能由相邻两台服务器来服务。
但是缺点也是因为这个,一台服务器的负载只能分到相邻两台服务器。
在实现时,两副本中一份记为主副本,一份记为备副本,读请求既可以从主副本读,也可以从备副本读。
但是写请求总是先请求主副本,只有在主副本挂掉的时候才从备副本服务。
处理读请求时,先从一个副本读取,如果成功就返回,如果收到服务器返回的失败信息,则客户端重试另外一台服务器。
但是如果请求是因为网络或服务器宕机超时,客户端就会交替地发请求给主和被副本,只要其中一个成功了,就算请求成功。
处理写请求时,服务器收到写请求时,先判断该服务器上是否是该数据的主副本,如果是,就先把这块数据标记为busy(持久化了),然后写日志(wrie-ahead-logging),
之后才同时发送写请求到本地和另外一个副本。
当两个请求都成功后,才清掉busy标记,然后返回客户端成功。
如果在更新的时候主挂掉,就可以通过busy标记来恢复,这样来保证主备一致。
如果写请求到的服务器的那份数据是备,则先要确保主已经挂了,才能服务该请求。这种情况下,标记该数据为stale(持久化),后续主进行恢复时,就需要判断stale标记。
如果主没挂(论文中没写怎样处理),不过猜测是返回客户端失败(有错误码),然后客户端发请求到另一个副本的服务器。
实现及测试
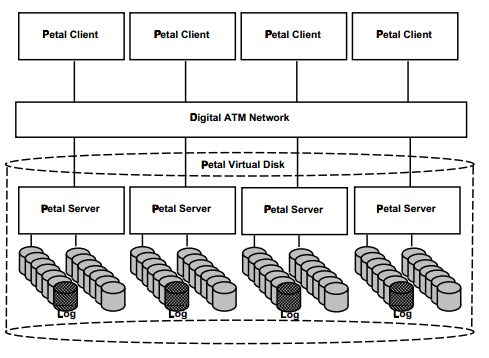
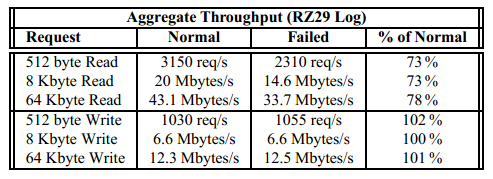
创建一个vdisk和快照一个vdisk的时间都大约是650ms
客户端请求的延迟时间对比:
使用内存盘做日志盘,相比于使用RZ29盘做日志,延迟时间减少了7ms;
相对于本地磁盘,64k的读也有7ms的差距,主要是网络的开销。
写请求因为要写日志,并且加上网络的开销。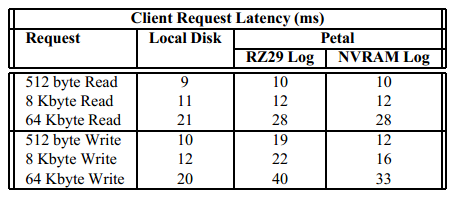
正常和有一个server挂掉情况下的吞吐对比