有些应用容许少量的数据丢失来换取高吞吐量,有些应用如数据库,邮件服务器是不容许一点数据丢失的。
posix应用使用刷盘(disk flush)来保证写的顺序,从而确保即使崩溃了仍然能够保证一致性,但是flush会有write barrier的问题,降低了并发性。
Blizzard并行地把对虚拟盘的读写发到远程disk上,有几个特性:
1)架构在CLOS网络上,全对分网络,读写每块disk都能达到全速,每个server
2)Nested striping,传统的会存在IOp convoy dilation问题,大的io会被文件系统拆分成小io,这些小io会从客户端发到一个远程disk,这些io都属于一个大的io操作,网络抖动,客户端服务器的调度异常都会使得请求间的间隔增加,而Bllizard使用Nested striping来解决这个问题,提高并发性,减少磁盘的热点。其实就是说一个大的用户io会拆分成多个小的io,但是这些io分别到达远程disk,如果这些请求到达远程disk时间间隔很短,远程disk就可以进行合并,然后一次寻道就可以读写,但是如果网络抖动,客户端服务器的调度异常都会使得请求间的间隔增加,这样就会造成远程disk要多次io,降低了性能。
3)Fast flushes with prefix write commits(异步刷数据),当收到flush请求时,立即返回给客户端,然后在后台异步地执行flush。即使客户端或者虚拟卷崩溃,该盘仍然能够恢复到一致的状态,不同flush epoch的写操作不会相互混乱,不过某个epoch之后的数据会丢失。使用异步写来提供性能,不过会有数据丢失的可能。
Design
posix应用的两种负载
通常是32kb-128kb的随机io;posix应用使用fsync()来控制写的顺序和持久化,需要确保在一个写持久化之前的其他写操作都已经持久化了,这样系统崩溃时就能够保持一致性。不过fsync就会引入write barrier,而write barrier就会降低并发性,Blizzard就需要处理fsync这个系统调用,使得能够保持写的顺序性,但是又不用用户同步等待写刷新完成。
实际上,Blizzard就是使用最终一致性来提高性能。
Blizzard的虚拟卷跨多个远程disk,能够利用并发来提高性能。并且其架构在cross-rack网络上,能够保证端到端的全速流量。一般的intra-rack网络,是网络超瘦,可以提高利用率,节省成本,不过对于突发的流量就不好控制,如果共享这个网络的客户较多,并且都有突发的流量,那么互相就有影响。
Blizzard基于FDS做的,FDS是一个分布式文件系统,使用CLOS网络来保证端到端的全速网络流量,FDS将blob划分成8MB的segment,称为tract。这些tract作为分条(strip)的单元。
FDS为大块的顺序写进行了优化,将每个FDS的blob拆分成很多大的tract,一个tract对应一个disk上的一段连续空间,一个blob的tracts跨越多个disk。
Data placement
tract是8MB的大小,但是posix io通常远小于8MB的大小,因此Blizzard就需要把对虚拟卷的随机小io映射到FDS的tracts上。
FDS提供一个接口,能够让应用以chunk的形式读写,chunk的大小小于tract。这个接口能够让应用处理tract的元数据的读写(小io)而不用读写整个tract。
第一版的Blizzard使用了这个接口,使用一个简单的映射就将虚拟卷的地址映射到tract级的偏移。整个虚拟卷的空间划分成多个连续的tract大小的chunk,每个chunk对应一个tract,然后一个虚拟卷的io偏移byteOffset ,就可以对应tract的byteOffset/TRACT SIZEBYTES。这种映射虽然简单,但是性能很差。连续的io经常命中同一个tract(因此同一块磁盘),从而降低了并发性。并且还会出现上面提到的IOp convoy dilation问题。
因此,使用一种新的映射方式,nested striping。定义segment为一个逻辑组,包含一个或多个tract,有点类似cache中的组相连,所以不需要维护这个映射关系的元数据,确定了block size和segment size,就确定了映射关系。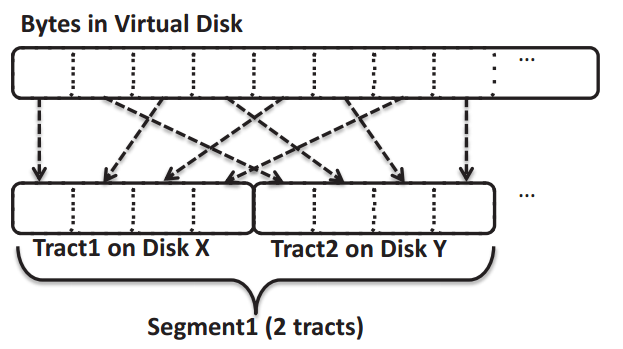
之所以叫nested,是因为Blizzard将block交叉地映射到FDS的tracts,然后一个blob里的tracts又是分布到多个远程disk。这样就能够提高并发性。默认一个segment使用128个tracts。
相对云硬盘来说,Blizzard打的更散,利用大并发性来提高系统性能,主要是针对随机io场景。而NBS一个chunk是10G,并发性没有Blizzard高。
测试结果表明nested striping能够减少IOp convoy dilation的影响,一个segment 128个tracts能够达到1000MB/s的顺序读吞吐率,1个segment 1个tract能够达到222MB/s的顺序读吞吐。
Role-base Striping
Blizzard既能够用于公有云,也能够用于私有云,不同用户有不同的性能要求,管理员能够调整segment中的tracts来控制系统的并发性以满足用户的需求。
Write Semantics
提供三种写策略
1)Write-through
最终一致性,同步写到FDS,性能较差。
2)Flush epoch commits with fast acks
一个flush epoch包含一个或多个写请求,当它的写都被刷到远程磁盘持久化后,这个flush epoch就可以被释放了。
Blizzard维护一个计数器epochToIssue,初始为0,表示哪个请求能被发到FDS;还维护一个计数器currEpoch(也是从0开始),这个表示已经发送的flush请求的总数,currEpoch总是大于epochToIssue。
当Blizzard收到一个写请求或者flush请求时,它立即返回给客户端,让客户端可以处理更多的请求。如果是个flush请求,currEpoch加1;如果是个写请求,它会使用currEpoch的值给这个写请求打上标记,并且把这个写请求放到一个队列中,这个队列以epoch标记排序。
Draining the write queue:一旦新的写请求放到队列中,Blizzard就会尝试发送队列中的请求到远程disk上,从头到尾遍历队列(从最老的epoch到最新的),如果被检查的请求是epochToIssue,则从队列中取出并立即发送出去,否则终止遍历。当一个epoch N的写处理完后,Blizzard检查epoch N是否退休,如果是,则递增epochToIssue,然后尝试发送队列中的新的请求。
当处理一个写时,它会把写请求从队列中移除,不过会存放在一个单独的cache中直到成功写到远程disk上(持久化)。在此期间,如果相同偏移的读请求到来,则可以直接从cache中读出,而不用去远程读。
从上面的描述中看出,Blizzard这种写策略是最终一致的,在系统崩溃后,只保证某个epoch之前的是一致的,但是之后的就有可能没有刷到远程disk上。
3)Out-of-order commits with fast acks
为了最大化写的处理,Blizzard提供一种方式,允许写请求立即返回给客户端,并且立即在后端刷到磁盘,而不用管flush epoch。
这样就会导致持久化的数据时乱序的(有可能后写的数据先被持久化),为了采用这种策略,Blizzard放弃了nested striping,而是使用一个log结构来避免就地更新。这样,即使一个写的数据持久化失败,也能恢复到一个一致的版本。然后,它使用一个确定的排列来决定哪个log entry(
假设虚拟卷有v个block,每个block等大,这个大小反映客户端的平均io大小(64KB,128KB),这v个虚拟block对应FDS底层blob的p个物理block(p>v)。Blizzard将物理block视为log structrue。维护一个blockMap来记录虚拟块到物理块的映射,另外再维护allocationBitMap来表示哪个物理块被使用了。处理读请求时,查询blockMap找到对应的物理块,从物理块中读出数据。
Blizzard维护一个currEpoch,每收到一个flush请求,currEpoch都会加1,所有写请求都被打上currEpoch标记,另外还维护一个lastDurableEpoch计数器,表示这个epoch的所有写都被持久化了,并且这个epoch是满足这个条件最新的。
The virtual-to-physical translation:当Blizzard初始化虚拟卷时,就生成了一个确定的物理block的排列顺序,这个排列表示了Blizzard更新log的顺序。比如顺序是18,3,…,然后第一个写就会发到物理块18,第二个到3。
使用同余,Blizzard只需要保存4个参数(a,c,m,另外一个表示排列中的当前位置)(线性同余算法X(n+1) = aX(n) + c(mod m),用来产生随机数)
一开始确定好a,c,m,X0,然后每次根据公式算出后一个X值,所以只用记录a,c,m,Xk,下一次就可以得到Xk+1。
当一个写请求到来时,Blizzard调用排列的函数,将写请求发送到allocationBitMap中第一块没有被使用的物理块。当写请求被发送后,并没有立即更新allocationBitMap或者blockMap。当写请求被Blizzard发出后,它把该请求发到一个队列里。当一个写操作的数据被持久化(写成功),根据排列的顺序,Blizzard检查这个写请求是否是lastDurableEpoch+1中最老的一个没有被处理的,如果是,就移除相关的写队列entry,并且更新blockMap和allocationBitMap;否则等待更老的写请求提交。一旦一个epoch下的所有写都已经持久化了,就递增lastDurableEpoch。
当Blizzard发送一个写请求到FDS,它实际上是写到一个扩展块上,包含数据,虚拟块的id,写请求的epoch号,整个扩展块的CRC校验。
如果客户端的写请求小于虚拟块的大小,就需要读出这个虚拟块的部分数据,然后计算CRC后再写到扩展块。read-before-write会有一定的性能损失,为了优化,Blizzard的虚拟块大小应该要和客户端的io大小匹配。一般像数据库和邮件服务器都有一个“page size”的配置项,因此对于这些应用Blizzard就需要配置虚拟块大小为应用的page size;不过对于其他写请求不是虚拟块倍数或者没有对齐到虚拟块的应用,Blizzard应该配置成write through或者Flush epoch commits with fast acks模式。
Checkpointing:客户端周期性地检查(Blizzard客户端)blockMap,allocationBitMap,4个参数和前面这些数据的CRC。对于一个500G的虚拟盘,检查点的大小是16MB,Blizzard并不是就地更新检查点,而是在FDS的blob上保留两个检查点的足够空间,在这两个位置之间交替地检查写操作(如何交替检查?)
Recovery:为了从崩溃中恢复,Blizzard加载两个序列化的检查点,并且使用有最大lastDurableEpoch和一个有效CRC的检查点初始化自身,然后从检查点中的排列的位置(4个参数中的其中1个)开始回滚,以排列的顺序扫描物理块,由于之前Blizzard以epoch顺序处理日志写,现在也是按照epoch’的顺序扫描处理。如果当前被检查的物理块在allocationBitMap中被标记为use状态,则继续检查下一个物理块;否则,检查这个物理块的epoch号,如果小于lastDurableEpoch,则结束回滚。如果一个物理块的所有副本的CRC不一致或相互不匹配,则终止回滚。否则,在allocationBitMap中标记该物理块为use状态(该虚拟块对应的旧的物理块标记为unuse?因为一个虚拟块只能映射一个物理块,相当于之前的那个物理块就可以回收了),并且更新blockMap映射表,指向该物理块。最后,将该物理块的epoch设置为lastDurableEpoch的值。回滚终止时的排列中的位置就是Blizzard下次发送写的位置。
比如,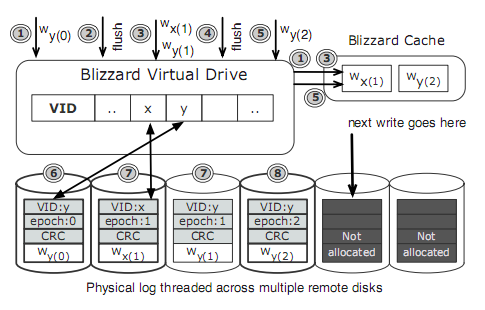
图中加粗的是已经持久化了的。
为了简单,图中使用的writeNumber % logSize来排列,因此物理log entry是从左到右线性扫描的,
在time(1)的时候,一个写虚拟块Y的请求到来,Blizzard立即写到远端,然后写数据放到内存中以便于读能够命中,
在time(2),一个flush请求到来,Blizzard立即响应给客户端,epoch是增加到1.
在time(3),写虚拟块x和y的请求到来,立即响应给客户端,并且并发地下发到下一个日志位置(还会更新内存中的Y)
在time(4),另一个flush请求到来,立即返回给客户端,并且epoch版本变为2.
在time(5),又一个写y的请求到来,写到下一个日志位置(并更新缓存中的y),
在time(6),第一次写y的请求已经在远程disk上写成功持久化了,Blizzard就会在blockMap中更新映射,使得y指向这个物理block
在time(7),写x的请求也已经在远程disk上持久化了,更新blockMap中x到物理块的映射,但是第二次写y还没有持久化成功,
在time(7),客户端记录一个检查点(注意客户端知道的最新的排列的index是第二个log entry)
在time(8),第三次写y已经持久化成功,但是因为第二次写y还没有持久化成功,不会去更新blockMap映射,因此,虚拟块y仍然还指向epoch为0的那个物理块。
假设客户端在time(7)做了检查点后挂掉了,并且假设这次挂掉阻止了写第三块物理块数据的持久化,当客户端重启后,它从检查点提出最后被更新的排列的index(log entry two),客户端按照排列的顺序回滚,检查第三块物理块log entry,发现在allocationBitMap被标记为unuse,然后检查对应的epoch号和CRC,因为这个写失败了,这些值的某个是错误的,这时客户端就停止回滚。尽管第四块的写y已经完成了,但是对于客户端来说,这次写就丢失了,但是客户端仍然恢复到一个一致的状态,
IOp dilation:线性的同余的排列方式,使得分散到足够多的disk上,也能够减少IOp dilation的影响。
Application-perceived Consistency
write-though能够最大程度的避免数据丢失
另外两种为了提高性能,会有一定程度的数据丢失,对于一些应用来说,能够容忍一定量的数据丢失来换取高性能,如果不能容忍,则采用write-through模式。
Server-side Failure Recovery
Blizzard依赖FDS来恢复失败的tracts,FDS在写失败后会进行重试,因此,Blizzard在检测到写FDS失败后,需要去FDS的元数据服务器重新获取tracts到disk的映射关系,然后再进行重试,如果启用了多副本,Blizzard会保证对虚拟卷的写请求成功写到远程的R个副本上。
Coexisting Workloads
Blizzard和FDS共用资源,不过单块盘要么给Blizzard的应用,要么给FDS的应用使用,以减轻相互间的影响。为了降低延迟,分配策略防止小io排队在大io的后面。
Implementation
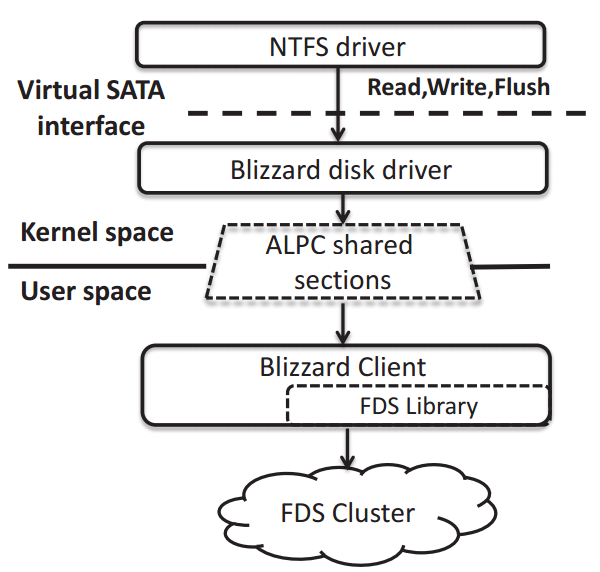
虚拟盘包括两部分:一个内核态的SATA驱动,一个用户态的组件用来连接FDS client library。
文件系统(或应用)发送io请求包(IRPs)到Blizzard disk driver,驱动把请求发到Blizzard client,然后Blizzard client会调用FDS的库把请求发往FDS,当请求处理完返回给Blizzard client,它把响应发给driver,然后driver通知应用这个IRP完成。为了减低用户态和内核态交互数据的开销,使用Window’s Advanced Local Procedure Calls (ALPC),它使用共享内存来提供零拷贝的IPC调用。
为了提高性能,在内核驱动,FDS client,FDS cluster之间的数据交互使用异步,Blizzard client使用多线程,不过这种多线程和异步的情况下,prefix semantics就很难保证。
内核驱动按照顺序把读写请求发到Blizzard client,但是client多线程,不同的请求在不同的线程里,这样发到FDS的写请求就是无序的,就需要一个全局变量记录每个epoch的写操作数目,多线程就会对这个全局变量争用。
为了在Blizzard client实现prefix semantics,内核驱动给每个写请求打上几个标记:flush epoch,这个epoch内的顺序号,前一个epoch的最大写顺序号。因为内核驱动是顺序发送请求的,知道每个epoch中的写请求数目。这样,不同的用户态线程就减少了对上面提到的全局变量的争用,因为知道了epoch中该请求的顺序号,虽然最后Blizzard把请求加到写队列里时也会有锁竞争,不过这个在io路径的第二部分了,io路径的第一部分已经解放出来了。
Evaluation
使用128块远程disk,单副本,write-through模式,不同block size和segment size的测试结果对比.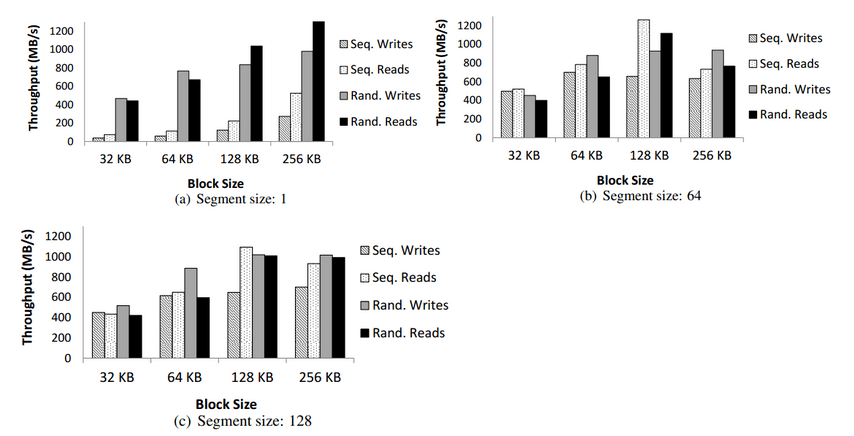
顺序写能达到700MB/s的吞吐量,顺序读,随机写,随机读能达到1000MB/s.
对比(a),(b),(c),在segment小时(为1时很明显),顺序io的性能较差,就是由于convoy dilation的影响。但是随机的io仍然能够达到比较好的性能(>400MB/s),这是因为随机io能够访问更多的disk,增加了并发性。block size超过32KB能够提升一定的性能,这是因为disk每一次寻道能够获取更多的数据,不过超过128KB性能反而下降了。